
Your Orchestrator Is An Exponential Slop Machine

gstack’s browser docs promise 0 tokens of context overhead per call.
“Plain HTTP, plain text, lighter than MCP.”
At the transport layer, maybe that’s true. At the workflow layer, one /autoplan run expands into at least 60,600 to 103,500 tokens before any output.
What are orchestrators anyway?
Orchestrators, swarms, agent teams, virtual engineering teams or whatever else people call them, are everywhere right now. Their promise is simple: you keep the human in the loop, wrap the model in more structure, add planning and review for safety, and somehow get software faster without losing rigor.
There are many examples with gstack being one of them. It is presented as a lightweight local browser-agent stack and as proof that high-velocity AI-assisted development can produce useful engineering workflows.
People were making fun of garryslist, a public product of gstack. A widely shared third-party audit found a single homepage load pulling 169 requests and 6.42 MB for what is basically a personal blog. That sparked my interest to look under the hood and ask why the end-product felt so bloated.


For those that don’t know me: I’m a developer who cares about programming as a craft. What bugs me about the current coding-agent hype is that it rewards exactly the instincts decades of coding taught me to resist: more surface area, weaker boundaries, thinner verification, and confidence that has nothing behind it.
It’s not as if I never produced my fair share of sloppy code. I did. But then someone else reviewed it or a proper CI/CD path caught it before it shipped.
The current hype seems to celebrate skipping all of that. And if you object you “just don’t get how software gets made now.”
I can get behind that thought. Software does get made differently now, but I think differently should still mean correctly and with care.
The browser layer in gstack may be light. The workflow behind it is heavier, less uniform, and less proven than the public surface suggests. Maybe the output is useful. But useful output you can’t explain is not leverage. It’s debt. It’s likely to be unoptimized and bad!
This is supposed to be lightweight
gstack‘s docs also claim a 20-command session saves 30,000-40,000 tokens compared to chunkier tool protocols. And at the narrow transport layer, maybe that’s true.
But the repo isn’t pitched as “a slightly more efficient way to send browser commands.” It’s pitched as a software factory with public rhetoric about 10-15 parallel sprints. Once that is the promise, the question stops being about one HTTP call and starts being about the whole workflow.
The one command context bloat
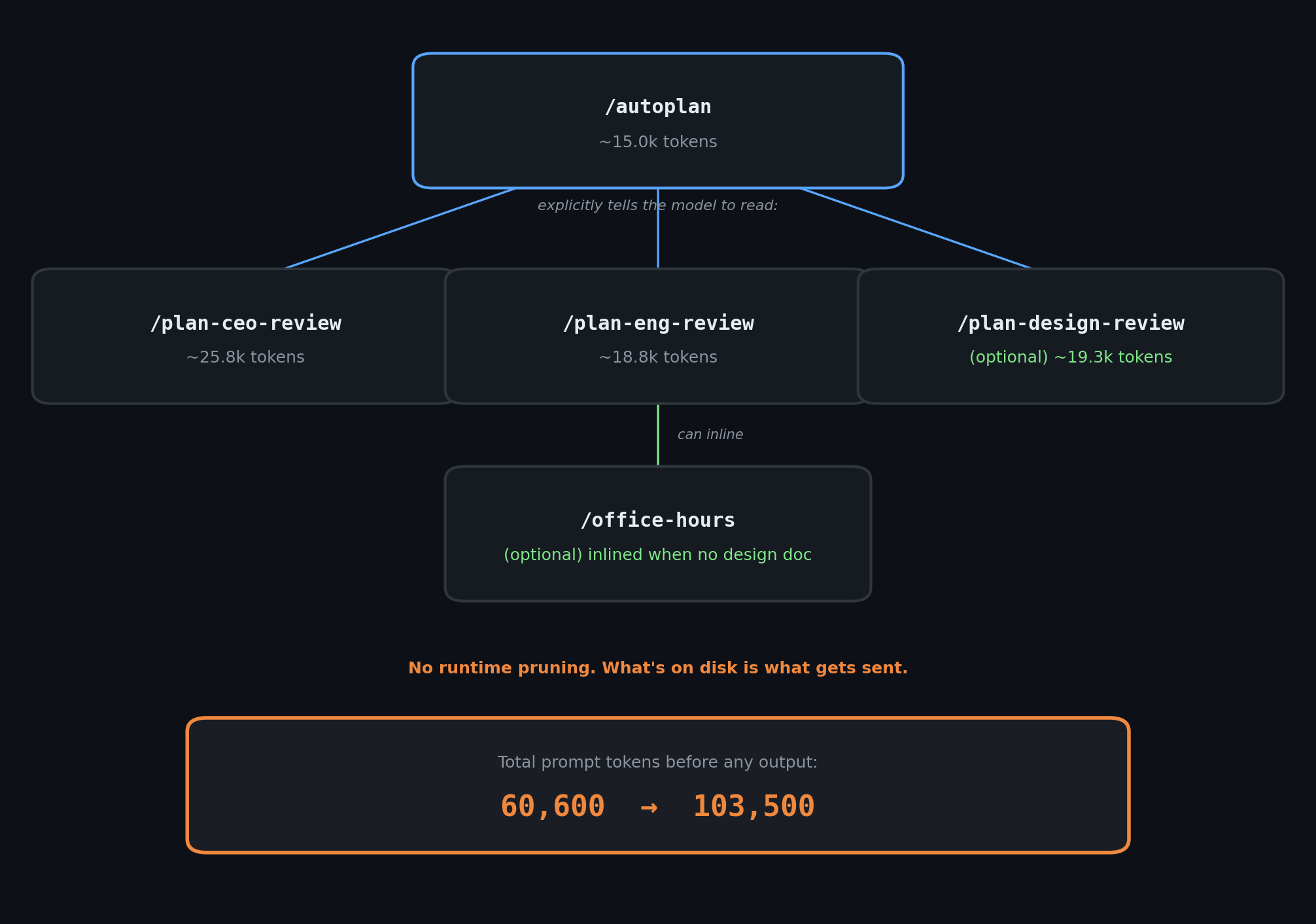
/autoplan is sold as “one command, fully reviewed plan.” The skill itself is about 15.0k tokens under OpenAI’s o200k_base tokenizer. It explicitly tells the model to read full review skills from disk:
/plan-ceo-review/plan-eng-review/plan-design-review(when UI scope is detected)
And those review skills can themselves inline /office-hours when no design doc exists, making the problem worse.
There is no runtime optimization between the skill files and the model. What’s on disk is what gets sent. No pruning, no compaction, and no token budget that trims content.
Claude Code’s own docs recommend keeping skills under 500 lines. gstack’s review skills are 1,200 to 1,677 lines each, and roughly 95% of that is duplicate voice rules, routing, and telemetry. The meat is about 50 lines per skill.
So “one command” is really a composed prompt path generating around:
60.6kwhen running/autoplan+ CEO + ENG80.8kwhen design review is also pulled in83.3kwhen/office-hoursgets inlined through the no-design-doc path103.5kwhen both design review and/office-hoursare in play
All of that is before the model writes a single token back, and before your own code, plan, or conversation history enters the context.
Large prompts alone are not necessarily evidence of bad engineering. But that defense only works if the public story is scoped honestly.
/autoplan is not some weird outlier. The total current-upstream generated skill surface is about 407,138 tokens plus a shared instruction set that keeps growing with each commit.
While not every token lands in one flat context window at once, the workflow always loads bloated instructions. Even gstack‘s own internal docs warn that full-skill reads in test fixtures cause context bloat and 5-10x slower runs.
That prompt load has a cost
Why should anyone care? After all, context windows are getting larger and token prices have fallen since the early GPT-4 era.
Because bigger windows don’t make prompt-heavy workflows free. They just raise the ceiling.
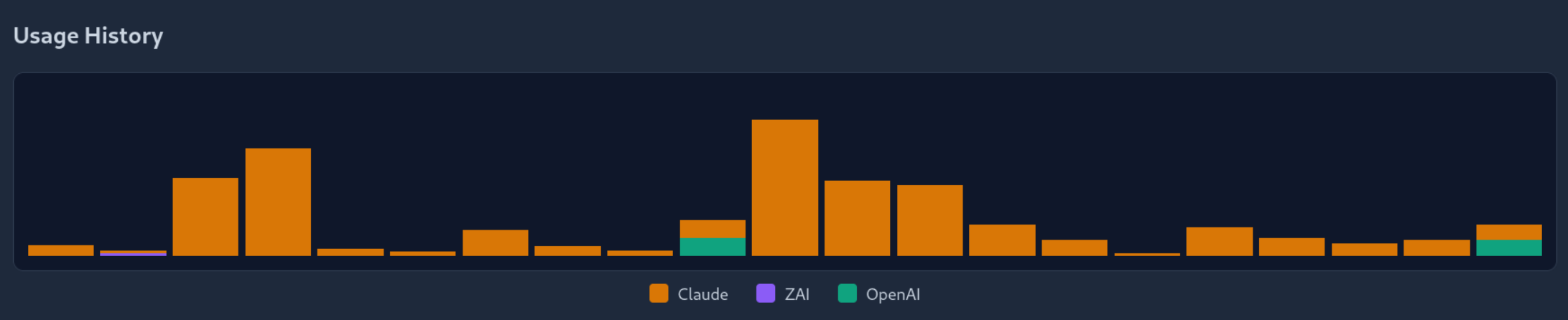
I do not have live gstack billing telemetry, so I am not going to pretend I do. But in my own separate orchestration tooling, built to send small, scoped tasks to isolated, headless agent sessions, the usage dashboard logged 839.2M tokens in one month, with peak days above 100M tokens. Only for testing the framework across 4-6 small foo projects.
That might not be direct proof about gstack. But it shows how quickly token burn stops being a rounding error once you start vibe-coding full-time.
And that was without all the planning overhead. The repo’s own public rhetoric about 10-15 parallel sprints implies tens or hundreds of millions of tokens a month.
It rots too
AI-heavy systems don’t crash loudly. They keep producing output that looks fine while becoming harder to reason about, slower to operate, and more expensive to run.
Long, layered contexts only make this worse. The more prompt mass you accumulate, the easier it becomes for the important parts to get buried under the rest. Any engineer who has maintained a large system knows the feeling of complexity arriving faster than understanding. That used to be the signal to “slow the fuck down” . Now it’s the signal to add another agent.
Lost in the Middle found that bigger windows do not guarantee the right information gets used well, and Context Rot demonstrated that accumulated context can degrade performance while the outputs still look plausible. Get My Drift also shows that LLMs silently shift task behavior under accumulated external context without observable error signals.
Perpetual maintenance
gstack is not only growing code. It’s growing prompts, generated skills, host transforms, and test surfaces around them. This creates a self-reinforcing loop:
add more workflow surface
add more scaffolding to manage the surface
add more assurance to calm fears about the scaffolding
polish it until it looks mature
add to the cost of understanding and changing it
It’s real progress with a carrying cost that stays invisible next to the headline “look how much leverage this gives me.”
In traditional software, degradation shows up in metrics such as latency spikes, error rates and failing tests. In prompt-heavy systems the degradation is more subtle. The output still looks structured. The plan still has sections and the review still sounds thorough. If you don’t audit the system for quality, the LLM will gladly gaslight you.
Anthropic’s own harness guidance says long-running agent workflows need runtime visibility into degradation, not just static test coverage. Right now there’s no way for an ordinary gstack user to tell when context growth starts hurting their results.
But it’s test-driven!
This repo has meaningful tests, CI, and eval infrastructure. But look at what actually runs. The default bun test path does not cover the expensive workflow and cross-host lanes readers are most likely to assume are covered. The broader CI eval surface is real too, just selective:
PR eval workflows cover a selected set of suites
periodic eval workflows are real but narrower
direct Codex and Gemini suites remain small
The README says “All 31 skills work across all supported agents.” On Codex, Review Army is stripped entirely and the /codex skill itself is excluded. Factory Droid is still advertised with setup instructions, but the changelog says support was removed.
Anthropic’s own guide to agent evals makes the same point: real eval stacks are still partial and task-scoped. They don’t prove the whole product works.
I have seen the same pattern in my own codebase audits: plausible code, plausible fixes, plausible tests, plausible benchmarks, plausible docs. Each layer makes the next easier to believe, and confidence does not compound without a human in the loop.
As an adopter, you are being asked to trust a lot of workflow surface the tests don’t fully cover. Real enough to trust. Too opaque to verify.
Beyond one repo
gstack is not presented as a side project. It is used as public proof that high-velocity AI-assisted development works.
When systems like this get copied, vendored, and adapted, the cost is not only local:
more token spend and slower loops for adopters
more maintenance surface for teams that standardize on it: the prompts, the generated skills, the host transforms, the eval harnesses
more generated software that looks more mature than it is
more verification burden shifted onto downstream users
more low-trust surface that somebody else has to filter
There is nothing wrong with exploring these tools and building with them. I do it myself. The problem is what happens when plausibility compounds at every layer and nobody is accountable for the gap between what’s promised and what’s shipped.
The orchestrator produces workflows that look structured. The workflows produce codebases that look tested. The codebases produce software that looks mature. And somewhere downstream an end user trusts something that nobody along the chain actually verified, in a codebase that no human and no model can comfortably reason about anymore because it grew faster than anyone could understand it.
That is the real cost of the velocity obsession. More commits, more features, more LOC per day, all of it rewarding output volume over the kind of slow, careful accountability that catches the things these systems miss. When the reviewer is a model, the tests are generated, the docs are generated, and the velocity metrics all say green, who is left to ask whether any of it actually works the way the README says it does?
This is not just about one repo. In earlier investigations of LLM-generated code, the same pattern kept showing up: plausible output, plausible tests, plausible benchmarks. And a 20,171x performance gap hiding underneath. That codebase was itself a product of an orchestration suite with its own prompt packs and skill tokens.
20K LOC/Day showed 15,647 (!!) green tests across a codebase where the one measurement that mattered was never written. METR’s randomized study and GitClear’s large-scale repository analysis both confirm these patterns are not isolated to any single developer or tool.
Steve Yegge’s Gastown, another orchestration framework, hit 189,000 lines in two weeks. Its creator openly says he has never read the code. Users reported $100/hour API burns and auto-merged failing tests. Even Anthropic’s own Claude Code CLI leaked at 512,000 lines and was immediately scrutinized for a single 3,167-line function and ~250,000 wasted API calls per day from a compaction loop that had no retry cap.
Each time the scale was different: a single function, a full codebase, the orchestrator suite itself. The pattern keeps moving up one level. The buck keeps being passed.
It’s your code. It ships under your name. If you can’t explain what the workflow is doing, how many tokens it’s burning, and whether the tests actually cover what the README says they cover, then the tooling is not giving you leverage. It’s giving you plausible deniability.
The craft hasn’t changed. Somebody still has to check.
- Hōrōshi バガボンド
Also published on X:

Sources
Primary Evidence
gstack repository, current upstream at commit
6169273. Token measurements use OpenAI’so200k_basetokenizer against current-upstream generatedSKILL.mdfiles. No runtime pruning verified viascripts/gen-skill-docs.tsgeneration pipeline analysis.Claude Code Skills Documentation. Anthropic. Official skill format specification recommending skills under 500 lines.
Primary Research — Long Context & Agent Degradation
Liu, N. et al. “Lost in the Middle: How Language Models Use Long Contexts.” arXiv, 2023.
“Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Research, 2025.
Arditi, S. et al. “Get My Drift? Catching LLM Task Drift with Activation Deltas.” arXiv, 2024.
Primary Research — Code & Productivity
METR. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” July 2025.
GitClear. “AI Code Quality Research 2025.” 2025.
Industry Commentary & Engineering Guides
“Demystifying Evals for AI Agents.” Anthropic Engineering, 2025.
“Effective Harnesses for Long-Running Agents.” Anthropic Engineering, 2025.
Zechner, M. “Thoughts on Slowing the Fuck Down.” March 2026.
Third-Party Audits & Case Studies
@Gregorein. garryslist.org homepage audit thread. X/Twitter, March 2026.
“Diving into Claude Code’s Source Code Leak.” Engineers Codex, March 2026.