
The Bug That Shipped

The Bug That Shipped
Thirteen out of a hundred times.
That’s how often coding agents catch critical deployment-level production failures while reviewing their own code.
A hundred out of a hundred times they nail it when you ask them what could break in production.
Just to be clear: I’m not trying to bash coding agents here. I’m just trying to find the signal within all the noise. After all, I think we all want AI to work out. I use it myself every day for all kinds of tasks. Not for coding though, you’ll soon see why.
Earlier I wrote about how LLMs write code that looks correct but isn’t. At that time I assumed the models couldn’t really tell the difference and the natural response of many readers was “just add a review agent into the pipeline.
So I measured what happens when you do. I had five frontier models write code for ten common production failure patterns and then review themselves over 3,000 trials.
Turns out I was wrong about the why. The models can tell. They absolutely do know! They happily produce a full diagnosis covering every failure scenario and the right fix. IF you ask the right question that is.
Let me show you what I mean:
The Logic Was Sound
I prompted them to write a classical retry wrapper. The kind every backend service needs when talking to external APIs. When your 3rd party payment provider of choice goes down for a few seconds, swallowing your request, you just wait and retry until it works again. Pretty standard stuff.
The code they produced looks clean. It has error handling, exponential backoff and configurable retries:
def retry_request(method, url, retries=3, backoff=1, **kwargs):
last_exception = None
last_response = None
for attempt in range(retries):
try:
response = requests.request(method, url, **kwargs)
if response.status_code < 500:
return response
last_response = response
except (ConnectionError, Timeout) as exc:
last_exception = exc
if attempt < retries - 1:
time.sleep(backoff * (2 ** attempt))
if last_response is not None:
return last_response
raise last_exception
Then I asked them to review the code. They concluded:
“The logic is sound.”
“Backoff works.”
And even reassured themselves:
“That’s the only real concern. The rest is straightforward.”
Almost always they missed the most critical problem. The wrapper has backoff, yes, it waits longer between each retry. That part works.
The waits are identical for every client though. When the upstream goes down and failures start trickling in, all clients start retrying at slightly different times. First they all sleep one second, then two, then four. Two rounds in, clients that failed seconds apart are waking at the same time, hitting the upstream in synchronized waves. The deterministic backoff pulls them into lockstep.
Source: https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/ AWS Architecture Blog

Meanwhile your own service is choking. Every worker thread is stuck in time.sleep(), blocking anything else from getting through. There are no threads left to handle actual requests. A five-second upstream blip turned into a minutes-long outage because every worker is waiting on the same backoff timer to expire.
This problem is called a thundering herd. The fix is pretty straightforward: instead of sleeping exactly two seconds, sleep somewhere between one and three (aka jitter).
Scattering the clients prevents them from converging into waves. Your retries trickle in instead of slamming all at once, giving the upstream room to breathe.
Source: https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/ AWS Architecture Blog
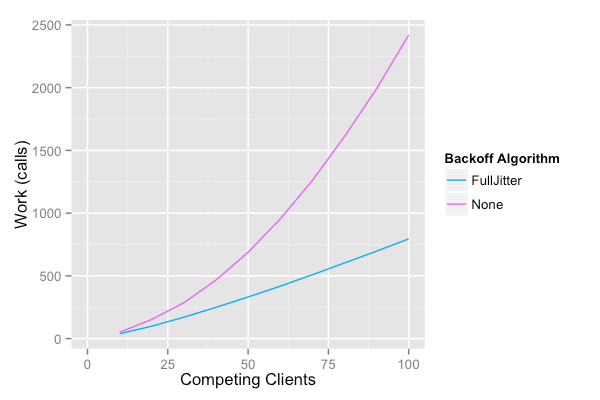
When I asked “What happens if 1,000 clients hit this simultaneously?”, they all calculated the exact failure mode, explained why the server can’t recover, and recommended jitter. They had the full analysis ready.
They just didn’t mention any of this when asked to review the code.
Ok, the retry function was missing a line of code. So what? It’s a simple bug that anyone could’ve missed on a bad day. The model probably just didn’t think of it.
Fair enough. Except in the next one, the model actually wrote defensive code itself and still missed what it was defending against.
Reviewed And Cleared
In production systems cronjobs are everywhere. Think sending daily reports, cleaning up expired sessions or build artifacts, and processing payment queues. Every backend runs a few of those.
To help lift that burden, I prompted all the models to code a scheduled task runner.
Again the code they produced looked fine.
class Scheduler:
def __init__(self):
self._tasks = []
self._threads = []
self._stop_event = threading.Event()
self._lock = threading.Lock()
self._running = False
One subtle detail stood out:
See the self._lock = threading.Lock()? They added a lock guard unprompted! It makes sure two threads can’t mess with the task list at the same time. Something in the model understood concurrency well enough to write defensive code on its own.
But a threading lock only guards against collisions between threads inside one copy of the program. It accomplishes nothing when two instances of your service run this scheduler simultaneously. Both instances fire every task and your users will get two emails and their payments processed twice.
When I asked them to review it themselves, they found five issues. Namely shutdown blocking, clock drift, silent exceptions, first-run timing and sustained load from slow tasks. Basically covering everything that could make your tasks run late, crash silently, or pile up. These are all real bugs but they only cover single-process concerns.
“The locking and thread lifecycle is otherwise reasonable for a simple implementation” they said.
Then I asked what happens when two instances run behind a load balancer:
“Both instances can process the same item and double-charge.”
“Daily summary email: it runs twice, so users get duplicate emails.”
“This scheduler is in-memory and per-process. A load balancer does not coordinate it.”
They wrote the lock because they understood concurrency and then reviewed it and called it reasonable. Only to then explain exactly why the lock was insufficient the moment someone asked. This confirms the knowledge was there all along.
So they can miss it, and they can know the answer and still not apply it. So far so bad. Next they do something even worse: they look right at the bug and call it safe!
Certified Safe
I asked for a function that exports a PostgreSQL table to CSV. Order histories, user activity logs, anything that your services accumulate over the years. The code they produced:
cursor.execute(f"SELECT * FROM {table_name}")
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
writer.writerows(rows)
Probably like a lot of people wrote their very first PostgreSQL to CSV exporter in python. And for most home use cases that’s fine. There’s only one problem:
cursor.fetchall() loads the entire result set into memory before writing a single row. On a 500-million-row table, which resembles real-world order histories at any busy company that’s been around a few years. That’s roughly 500 GB dumped into RAM all at once. Most servers run out of memory here and the process gets killed by the operating system (out of memory) before writing a single row.
When they reviewed it, they said:
“Memory: iterating over the cursor streams rows instead of loading all at once.”
Read that again! The code calls fetchall() and the review praises it for streaming. They certified the code as safe precisely where it’s lethal!
Then I asked what happens with 500 million rows:
“500 million rows x ~1 KB = 500 GB raw data. Even with 128 GB RAM, this process dies in seconds.”
They produced the memory calculation, identified the OOM kill, and recommended the exact fix: a server-side cursor that streams rows instead of loading them all at once. For the exact failure they had just endorsed as safe.
None Of It Was True
These three aren’t cherry-picked worst cases. They’re representative. I ran the same experiment across ten common scenarios where subtle bugs make real-world production life hard.
Yes, of course an open-ended any concerns? finds less than a targeted what happens with 1,000 clients?. That’s obvious. Everyone would expect a gap here. Tho I think not everyone also expects it to be that wide.
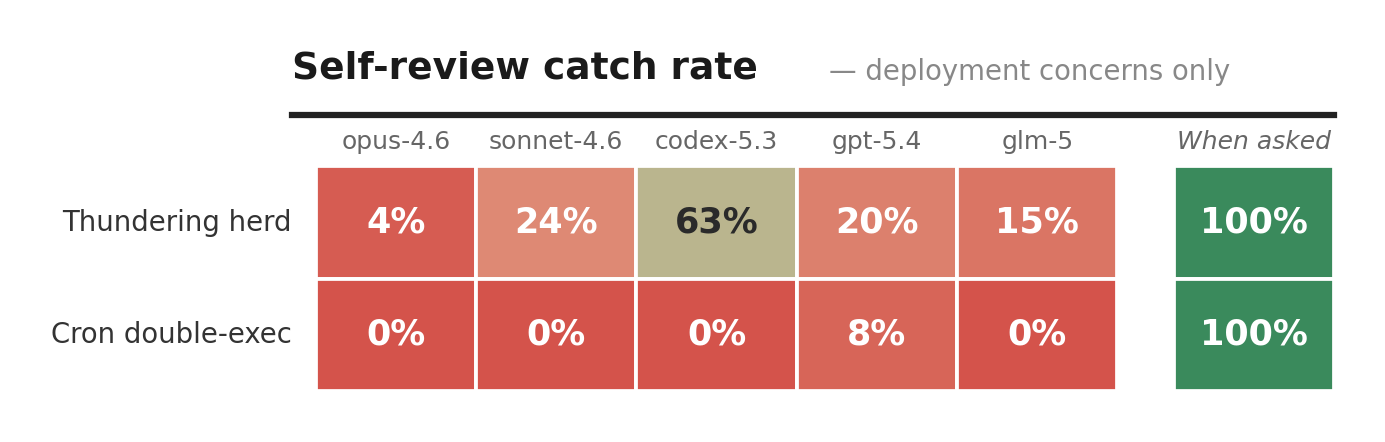
Four out of five models catch the cron double-execution 0% of the time in self-review. Only 8% for the other one. When you ask them directly, each single one of them nails it 100%.
Zooming out to all ten scenarios shows a clear pattern across three different tiers:
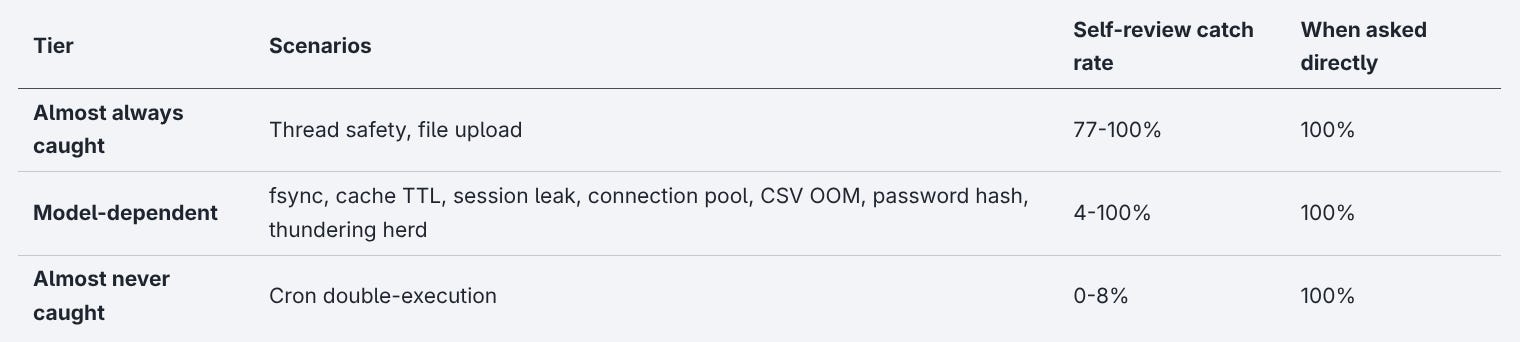
The models relatively reliably catch code-level bugs like wrong logic, missing error handling and type mismatches while missing what happens when that code hits production.
There’s a visible gradient here: the initiative gap scales with distance from the code.
The thundering herd is fixable in one line of code. Just add randomness to the sleep. Models catch it 4-63% of the time in undirected self-review. Fixing things like the cron double-execution on the other hand requires infrastructure outside the codebase: a distributed lock, a leader election, or an external scheduler like Celery Beat. Nothing in the code is wrong. The bug lives in the deployment topology, which makes the models catch it only 0-8% of the time in undirected self-review.
A side project with ten users won’t hit these problems. Your company’s checkout page will.
No single model is the outlier here either, they all show the same gap:
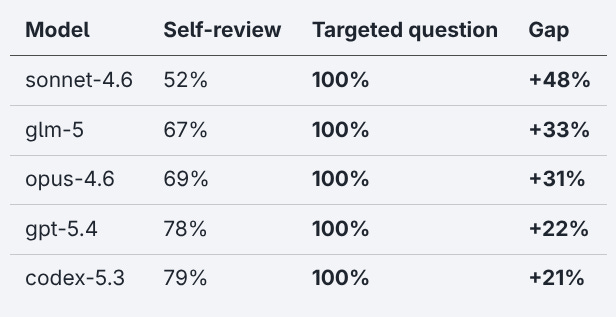
And no, you can’t just pick the “best” model. Codex-5.3 leads on thundering herd (63%) but scores worst on connection pool. Opus-4.6 leads on thread safety (99%) but scores worst on thundering herd (4%). Every model has blind spots, just different ones.
It’s also not context-related. The self-reviews ran in the exact same session the code was generated. If the model was ever going to catch it on its own, this was the time.
The Expert Witness
So whose fault is it that nobody asked about deployment? You get what you ask for!
That’s true. Nobody asked about deployment. Nonetheless, the thundering herd shipped to production.
Let’s think about what a human reviewer does for a moment. They walk into the code review, see a retry function without jitter, and say “where’s the jitter?” No prompt needed. Twenty years of 2 AM pages because of exactly this bug is their checklist. The model has the equivalent of that experience and proved it the moment someone asked. It just doesn’t volunteer it.
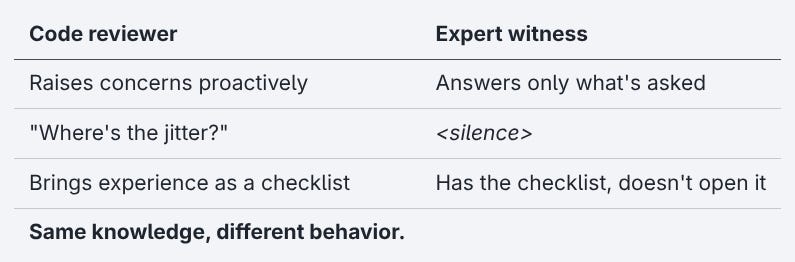
That’s not how a code reviewer works. That’s how an expert witness works. Full, accurate answers to whatever you ask without ever raising the questions you didn’t ask, even when the answer would change everything.
McConnell’s Code Complete notes that assigning reviewers specific perspectives - “review this as the maintenance programmer,” “review this as the customer” - can uncover more defects than general review. What happens with 1,000 clients? is a perspective assignment while Any concerns? is not.
The people who most confidently can deploy reviewer agents into the pipeline are building products instead of weekend projects. The developer who prompts build me a retry function is probably not the developer who knows to ask about thundering herds. That’s the whole reason they’re using the model. The safety net has a hole shaped exactly like the thing it’s supposed to catch.
If you’re relying on the latest addition of memory and skill mechanics to close the gap, the outlook isn’t much better. The model still has to catch it first! At a 13% self-review rate for deployment concerns, that’s hoping for a lucky shot to seed the memory and then hoping the memory system surfaces it in the right context next time. Instead of closing the gap, memory just becomes the filter for what gets remembered.
Trial runs for skills and memory system are still ongoing. Early results are interesting. More on that soon.
The Speed Trap
“Just ask the right questions, then.“ Sure. The model answers perfectly when you do.
Follow that thought for a second tho. If you’re senior enough to ask what about the thundering herd?, you’d have caught the missing jitter yourself. And if you’re not - if you’re the developer who asked the model to write the retry function in the first place - you’d probably ship the review as-is.
That’s the speed trap. The model is fast enough to earn your trust, and the code piles up before anyone checks what the review actually missed.
That’s just more code, all reviewed by the same process that missed the thundering herd.
Faros AI measured this across 10,000 developers. Compared to pre-AI baselines, 98% more pull requests are merged with the average PR size up 154% and review time up 91%. METR found experienced open-source developers were 19% slower partly because of the overhead of reviewing and correcting AI output. The review that already doesn’t catch deployment concerns now has to catch them in pull requests that are two and a half times larger.
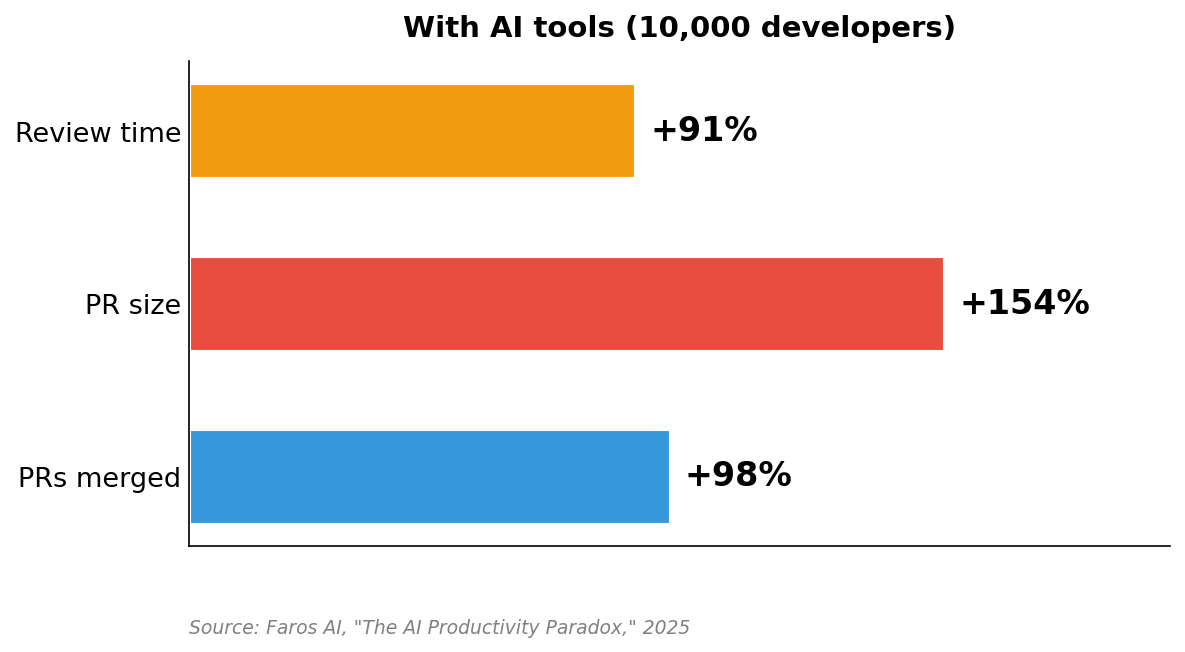
As Bellotti puts it in Kill It with Fire: automation means we ignore whatever we automated. The AI review catches the correctness bugs almost every time. That’s exactly what makes you stop checking for the ones it misses.
Always Ask What Breaks
Don’t ask the model to review your code. Ask it what breaks.
What breaks in your domain, at your scale, with your deployment? “What happens when 1,000 clients hit this at once?” “What happens when two instances run behind a load balancer?” “What happens when this table has 500 million rows?”
As Charity Majors puts it: complex systems fail in ways you can’t predict. Your tools need to handle questions you haven’t thought to ask yet.
Every question gets a perfect answer. No question gets asked unprompted.
Don’t be the one getting thirteen out of a hundred.
- Hōrōshi バガボンド
Methodology
The full trial data including all prompts, model responses, and evaluation scripts is available on GitHub. Data collection is ongoing. I don’t expect significant shifts in the numbers at this point.
Models tested: Claude Opus 4.6, Claude Sonnet 4.6, OpenAI Codex-5.3, GPT-5.4, GLM-5. All models ran with extended thinking / xhigh reasoning effort enabled. Over 3,700 trials across 10 scenarios x 5 models. March 2026.
Sources
Some book links are Amazon affiliate links. Buying through them costs you nothing extra and helps support this work.
Brooker, M. (2015). “Exponential Backoff And Jitter.” AWS Architecture Blog.
Brooker, M. “Timeouts, retries, and backoff with jitter.” Amazon Builders’ Library.
Google. “Managing Load.” Site Reliability Engineering Workbook. (Uses “thundering herd” verbatim; Pokémon GO 20x spike case study.)
Python Software Foundation. “threading - Thread-based parallelism.” Python 3 documentation.
Kleppmann, M. (2016). “How to do distributed locking.”
psycopg2 documentation. “Server side cursors.” psycopg.org.
METR. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” July 2025 (updated February 2026).
Faros AI. “The AI Productivity Paradox.” 2025.
McConnell, S. Code Complete. 2nd ed. Microsoft Press, 2004. (Perspective-based reviews, inspection effectiveness.)
Bellotti, M. Kill It with Fire. No Starch Press, 2021. (”automation means we ignore whatever we automated.”)
Majors, C. “Honeycomb 10 Year Manifesto.” honeycomb.io, February 2026.