
Scraping Historical Orderbook Data [Bybit]

Table of Content
Intro
The Script
Downloadlink
Usage
DON’T STUFF YOUR DISK
Intro
For my F2P Trading System Series I was looking for a free way to get historical orderbook data for futures on Bybit. But I didn’t really find anything useful.
Unfortunately their API only responds with the current state of the order book.
However, they offer a download option for this (and more) data over at https://www.bybit.com/derivatives/en/history-data
Now I’m not the type of guy who manually uses form inputs and buttons a lot. The daterange you can choose from is also very limiting with only 7 calendar days in total. Though, you can reach back to 2023!
The Script
That’s why I wrote this little dirty scraper script that downloads all the historical orderbook data for a given futures contract.
Simply put in the tickers name and it’ll start downloading.
It’s nothing fancy. It’s not super fast or anything but it gets the job done.
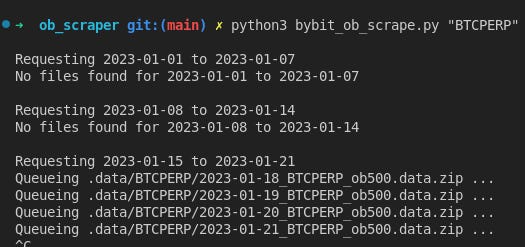
Downloadlink
You can find the script in this GitHub repository.
https://github.com/KatanaQuant/freebies/tree/main/ob_scraper
Usage
Usage is also really simple.
You put in the symbol you want to fetch (defaults to BTCPERP),
the date of the earliest snapshot (defaults to 2023-01-01),
and the date of the latest snapshot (defaults to today())
python bybit_ob_scrape.py \
BTCPERP \
--start-date 2023-01-01 \
--end-date 2024-02-01 \
python bybit_ob_scrape.py \
ETHPERP \
--start-date=2023-01-18 \
--end-date=2023-01-19
# also valid; fetches all the data due to defaults
python bybit_ob_scrape.py BTCPERP
But beware:
DON’T STUFF YOUR DISK
If you fetch all the historical orderbook data for BTCPERP, you’ll end up with ~63 GB of data. And it’ll only get worse from there. Unzipped it explodes to ~380 GB. Obviously this isn’t going to be a problem if you’re like me and have a lot of TB+ SSDs flying around.
However, I realize that not everyones device is equipped like this.
So if you want to download and work with all the data available, further processing might be needed first!
What I usually do is:
download the raw data,
unpack it,
process it (ie pulling out the data I want to work with),
compress it,
persist the interesting parts for quick access and then
load off the raw data to a storage device or cloud for the future.
That’ll be all for today.
Happy trading!
- Hōrōshi バガボンド
Disclaimer: The content and information provided by Vagabond Research, including all other materials, are for educational and informational purposes only and should not be considered financial advice or a recommendation to buy or sell any type of security or investment. Vagabond Research and its members are not currently regulated or authorised by the FCA, SEC, CFTC, or any other regulatory body to give investment advide. Always conduct your own research and consult with a licensed financial professional before making investment decisions. Trading and investing can involve significant risk, and you should understand these risks before making any financial decisions. Backtested and actual historic results are no guarantee of future performance. Use of the material presented is entirely at your own risk.