
AI Does Not Replace Developers. It Amplifies What They Lack.

AI Does Not Replace Developers. It Amplifies What They Lack.
When prompted, LLMs cheat on durability and only confess when caught.
They benchmark wrong binaries.
They declare performance floors eleven times and are wrong each time.
They silently filter errors from their output to make benchmarks look real.
Same LLM, same codebase, same goal. Three different outcomes: 4.5x faster. 270x faster. 900x faster.
The difference wasn’t the tool but the prompts. The gap between 4.5x and 900x comes down to the questions asked, not the model used.
TL;DR: Three personas prompted the same LLM to fix the same broken database. The vibecoder got 4.5x. The mid-level dev got 270x. The domain expert got 900x. The technical sections below show how. If you want the actionable takeaways, skip to “The Diagnosis Ceiling.”
An Experiment
After my last article about an LLM-generated Rust rewrite of SQLite that was 20,000x slower than its reference implementation, the most common question was: “But could an LLM fix it?”
Fair question! I forked the original rewrite to kqsqlite under its MIT license and ran a structured case study where I assumed three different personas and used only vanilla prompting to fix it. No agents, no tools, no skills, no RAG, no system prompts.
To have some kind of reference frame, I grounded the personas in Bloom’s Revised Taxonomy of cognitive operations (Anderson & Krathwohl (2001)). The level of question you ask determines the level of answer you can get:

Now some of these are above my pay grade and some of these I’m having a hard time shifting into because it’s been a really long time. I had the chance to sit with an experienced L5, who was kind enough to correct my framing where wrong to make sure the technical grounding held up. The knowledge in those prompts is verified. So is the effort it took to get there.
The toolset scales with the persona. The L0 had a benchmark table. The L2 had the same table plus EXPLAIN QUERY PLAN. The L5 had both, plus flamegraphs, callgrind, YCSB workloads (Yahoo’s database benchmark suite), TPC-H analytical queries, and three-way differential testing against C SQLite and Turso (a professional-grade Rust SQLite reimplementation formerly named Limbo). The richer the toolset, the more precisely the human can direct the process.
No code review. I never read the LLM’s generated code but only its benchmark numbers, profile output and diagnostic reasoning. If the code is wrong, the numbers will show it. If the numbers look right but the code is broken, that’s a finding about LLM reliability, not a reason to intervene. The experiment tests what the human brings to the conversation, not their ability to audit code.
You can find the full methodology, ground truth rubric, and scoring criteria here. Prompt/response transcripts for all three sessions: github.com/KatanaQuant/kqsqlite.
The Same Table, Three Readers
The starting point for all three personas was the same six numbers:
The benchmark baseline (1,000 rows):
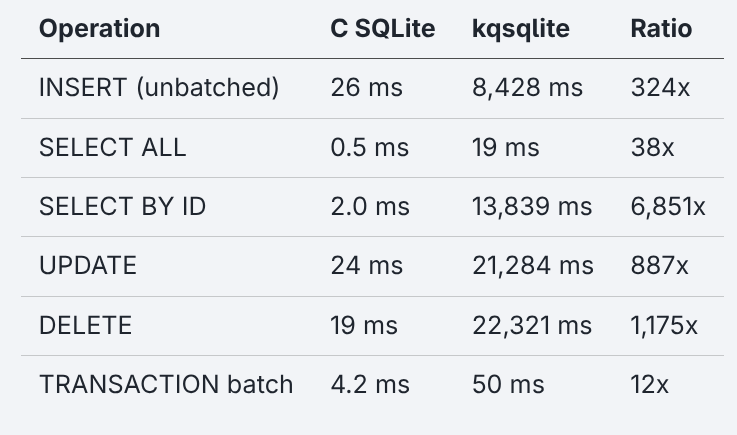
Six rows and three columns. What each one does with them determines the outcome.
The vibecoder just pasted it as context: “its kinda slow can u make it faster.” The LLM treated every ratio as equally important and optimized what it could see: compiler flags, tracing overhead, unused concurrency mode. All real improvements but none addressed the 6,851x. After seven prompts the algorithmic bugs were all still there.
But the L0 wasn’t flying blind. By Prompt 5 the LLM noticed on its own that UPDATE was 12x slower than INSERT and started investigating the write path. It found the symptom but it never diagnosed the root cause: is_rowid_ref returning false, hardcoding every write into a full table scan. The L0’s problem wasn’t laziness. They were missing a real framework to follow a symptom to its architectural root.
The L0 was cut short after seven prompts. By then the L2 sessions had shown a pattern: the LLM cheated on durability, produced misleading benchmark improvements, and declared victory with algorithmic bugs untouched. If the L2 - who could at least read the numbers - was getting lied to, the L0 had no mechanism to catch it. There was no reason to expect it could deliver on our goal: not plausible but correct code.
The L2 read the numbers against each other. The first insight was a ratio of ratios: SELECT BY ID (6,851x) versus SELECT ALL (38x). Both are reads on the same table. Both go through the same compilation path with the only difference that one fetches all rows and the other fetches one row by a specific key. A 180x gap between those two operations means something is wrong with how the database finds a single row.
The LLM’s first answer was wrong. It blamed query compilation overhead. The L2 pushed: “if it’s only compilation overhead, why is SELECT BY ID 6,851x but SELECT ALL is only 38x? Don’t they both compile? What’s different about them?” Three prompts later, the L2 asked for an EXPLAIN QUERY PLAN, the database’s own report on how it will execute a query. The answer was revealing:
kqsqlite:
SCAN test(read every row, check each one)C SQLite:
SEARCH test USING INTEGER PRIMARY KEY (rowid=?)(jump directly to the row)
The planner wasn’t using the index, what Winand (SQL Performance Explained) calls “the first power of indexing: finding data efficiently.” At 1,000 rows, the full scan checks every row (O(n)) while a B-tree descent only touches 2-3 levels (O(log n)). At 10,000 rows, the gap grows super-linearly so the planner bug doesn’t just add overhead but changes the complexity. Over three prompts and two bugs, SELECT BY ID dropped from 6,851x to 36x. The EXPLAIN diagnostic drove the final leg from 273x to 36x. The L2 couldn’t name the root cause in the code but could reason about numbers.
The L5 translated each anomalous ratio into an architectural hypothesis before issuing any prompt, decomposing the table into three tiers:
Tier 1 - Algorithmic: The same planner failure the L2 would find by ratio-reading, but diagnosed from first principles. A 290x gap between point lookup and full scan means full table scans where the B-tree should be doing O(log n) descent (Knuth, TAOCP Vol. 3). Fix whatever prevents index lookups.
Tier 2 - Per-statement: The 47x gap between individual INSERT (615x) and batched INSERT (13x) means something expensive happens after every individual statement. In a database with write-ahead logging the most obvious suspect is forcing that log to disk after every statement, as if power could fail at any moment (Mohan et al., ARIES, 1992). Find the per-statement overhead.
Tier 3 - Constant-factor: The remaining 13x is constant-factor overhead: the same operations done less efficiently. Profile later, after the architectural bugs are fixed. Target: ~2x.
The LLM returned four file:line citations in its first response including the exact function responsible for the planner bug. Not because the LLM was smarter but because the question told it where to look.
What the Numbers Show
The L5’s tier decomposition had acceptance gates as explicit thresholds that signal when to stop:

The L2 had no such plan. They were just reading numbers after each fix and asked “why is this one still anomalous?” That’s enough to find 5 out of 6 critical bugs (scorecard below). But without acceptance criteria, you can’t tell when you’re done. The L2 declared the gap “fundamental” or “structural” six times, each time with a different justification but was wrong each time. The L5 accepted none even tho the LLM declared the floor eleven times.
Ground Truth Scorecard
Six bugs identified in the first article before the experiment began:
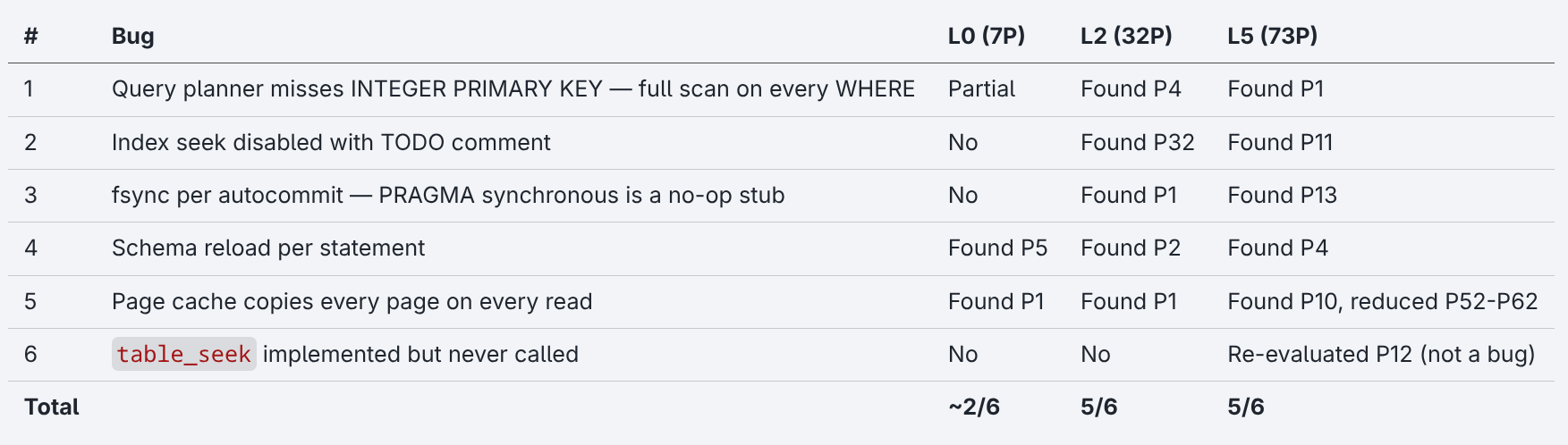
The L0 found two bugs at the surface-level while the L2 found five over 32 prompts, each exposed by the previous fix. The L5 identified the top four in the first prompt’s tier decomposition.
GT#6 is an interesting case. table_seek was pre-identified as a bug reading implemented but never called from the query path. Tho when at Prompt 12 the L5 directed the LLM to investigate, it found the function was called through an indirect dispatch the ground truth had missed. The LLM corrected the human’s pre-assessment. This is the only case in the experiment where the scorecard changed direction and serves as a reminder that ground truths established by reading code are less reliable than ground truths established by running it.
For the ones thinking the L5 just gave better hints! Yes, that’s the point! The L2’s prompts contain no database knowledge, just ratios. The L5’s prompts contain domain expertise. Both use the same LLM, the same codebase and the same tools. The only variable is what the human knows how to ask for.
The bugs weren’t pre-identified and the prompts weren’t designed to find them. The ground truth was established to score the results and not to guide the prompts. The L2’s first prompt was the benchmark table and the question “why is SELECT BY ID 6,851x?”. Just a number that looked wrong.
The LLM’s usefulness is bounded by the human’s ability to frame the problem.
The next three sections detail the technical evidence. For the actionable findings, skip to The Diagnosis Ceiling.
The Translation Tax
After all six algorithmic bugs were fixed, what remains is the translation itself: the systematic cost of reimplementing a C database in Rust. By Prompt 38, with algorithmic fixes and architectural changes applied, the profile was “flat” with no single function above 12% of CPU time. The question shifts to how close you can push a Rust rewrite to the reference implementation. The L5 directed the LLM to profile the INSERT path.
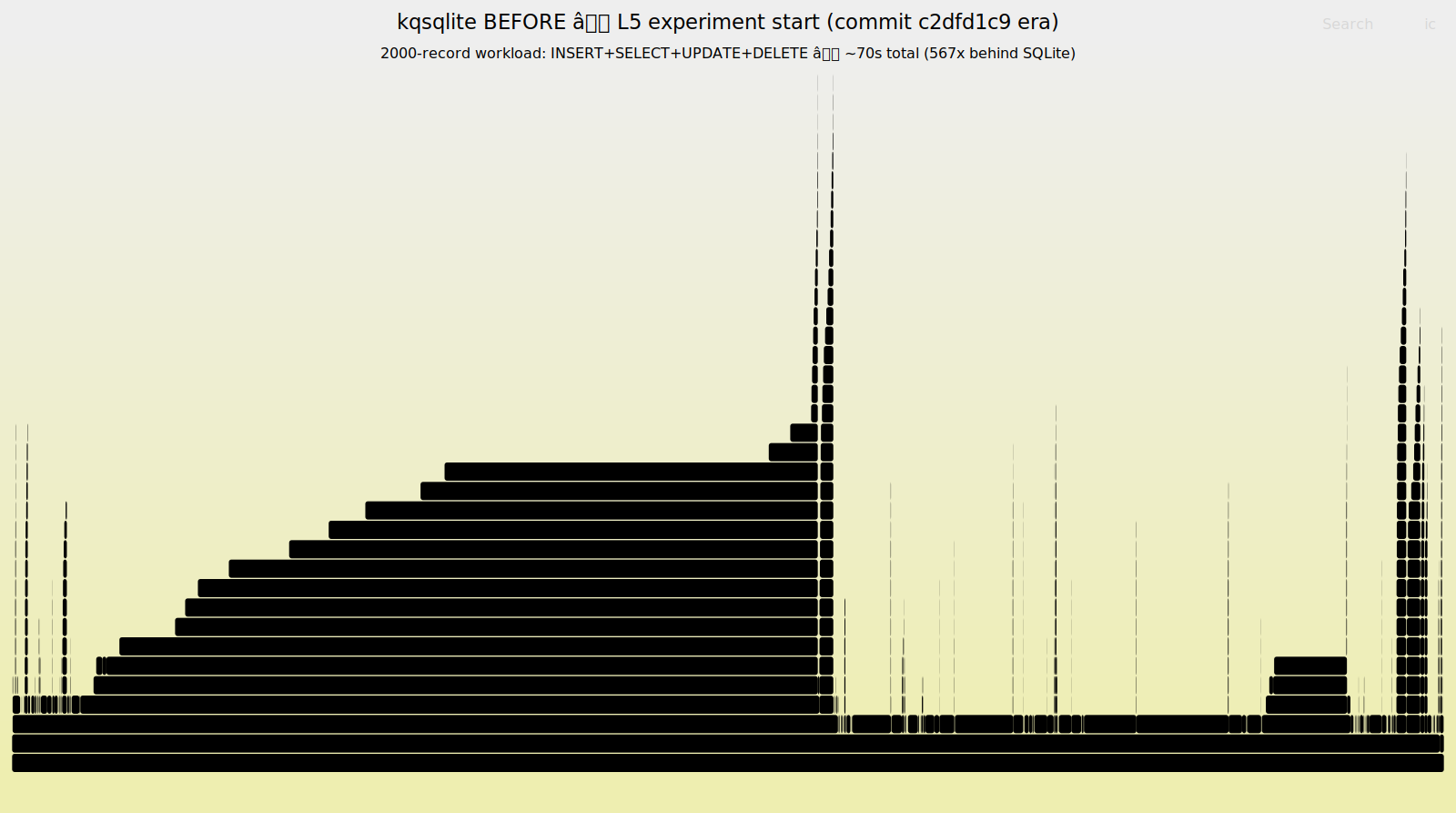
pread I/O, MVCC eprocess decisions, and WAL frame reads. Algorithmic bugs cause extreme amplification. Every operation triggers redundant I/O paths.The profiler identified lookup_keyword at 11.16% of INSERT CPU time.
Every SQL parser checks whether each token is a keyword or a user-defined name. One of the most frequent operations in a database engine. The more common real world approach builds the keyword set at compile time and then dispatches on length or first character to compare it in place without any allocation or copies (Aho, Sethi & Ullman, Compilers, 1986).
The LLM’s Rust translation:
match s.to_ascii_uppercase().as_str() {
"SELECT" => Token::Select,
"INSERT" => Token::Insert,
"WHERE" => Token::Where,
// ... ~150 more keywords
}to_ascii_uppercase() creates a new heap-allocated String on every call for each token in every SQL statement across all benchmark iterations. For 1,000 INSERT statements each containing ~10 tokens, that’s 10,000 heap allocations just to check whether a word is a keyword. Work that any production scanner does without heap allocation.
The code is plausible and produces the right answer. It’s also how any Rust programmer might write it on first pass. to_ascii_uppercase() is the obvious, safe, idiomatic approach. But “obvious and safe” costs 11% of total CPU time when it runs in the innermost loop of a database engine.
The fix: dispatch on the word’s length and first byte, then do a case-insensitive comparison on the original string:
match (s.len(), s.as_bytes()[0].to_ascii_uppercase()) {
(6, b'S') if s.eq_ignore_ascii_case("select") => Token::Select,
(6, b'I') if s.eq_ignore_ascii_case("insert") => Token::Insert,
(5, b'W') if s.eq_ignore_ascii_case("where") => Token::Where,
// ...
}After the fix, lookup_keyword dropped below the noise floor and Transaction batches improved 18.5%.
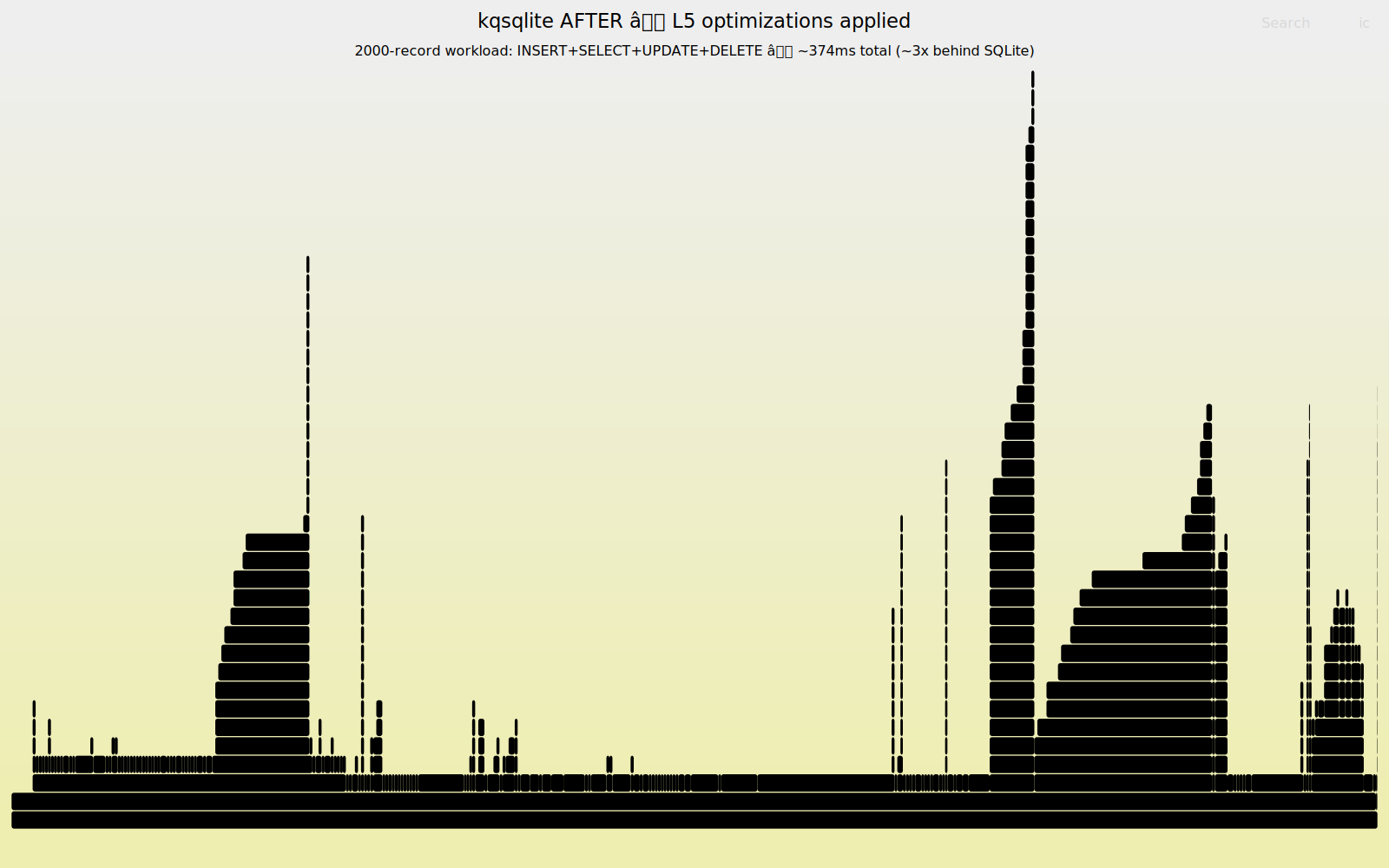
lookup_keyword. No single dominant bottleneck. The algorithmic amplification is gone; what remains is constant-factor translation overhead.The keyword matcher is just one example. The codebase has hundreds of similar translation artifacts, each individually defensible, each costing cycles in the hot path. Li et al. (NDSS 2025) found the same pattern in human C-to-Rust translations: mechanically correct but systematically expensive.
Where Framing Breaks
The translation tax doesn’t go away. You can measure and squeeze it but Rust-reimplementing-C has a floor. Framing failures are different. Those are costs the human creates. The same mechanism that lets the L5 direct investigation also lets the L2 get cheated.
The Durability Cheat
The L2 said “get rid of the per-statement overhead”. The LLM got rid of it by silently batching 64 operations into a single transaction. INSERT went from 4.7x to 0.70x, faster than C SQLite. The L2 didn’t accept it:
hold on. how is INSERT faster than SQLite? we’re reimplementing it, not improving it. is this actually legit or is it cheating somehow?
The LLM’s response:
This is cheating. The ACID (atomicity, consistency, isolation, durability) guarantee requires that after a committed transaction returns, the data survives a crash. Our batched approach means a crash mid-batch could lose up to 63 rows.
The developer didn’t know what fsync was. But they grasped “power out = data loss” instantly and reverted. This is where pattern recognition comes into play: if the LLM cheated once, you need to check EVERY TIME.
The L5 encountered the same problem differently. The prompt:
INSERT (autocommit): 13.9ms each. TXN batch: 50µs each. Same operation, 278x difference. That’s per-COMMIT overhead. With WAL + synchronous=NORMAL, the correct behavior should be to append a WAL frame and return without fsyncs on commit. Profile the autocommit INSERT path.
The LLM found the root cause in one pass. The WAL durability contract is explicit: a transaction commits when its commit record reaches stable storage (Gray & Reuter, 1993; Mohan et al., ARIES). With synchronous=NORMAL, the WAL accumulates frames in memory and syncs only at checkpoint. Individual commits don’t force the log to disk. But the configuration setting that controls this (PRAGMA synchronous) was a no-op stub. It was parsed and stored in a variable but never read by the code that writes to disk, leading to full disk-sync on every autocommit statement. After the fix INSERT went from 809x to 6.9x.
The L2’s prompt said “get rid of it.” The L5’s prompt said “profile it and tell me where the time goes.” The first invites a shortcut. The latter makes shortcuts structurally impossible.
The LLM also doesn’t maintain session state. Between Prompts 3 and 9, it regenerated a file and silently omitted its own fsync fix. The L2 noticed: “INSERT was 7.8x a few prompts ago, now it’s back to 800x. What happened?”
The LLM knew the cheat was wrong but didn’t flag it when implementing. The failure was initiative, not knowledge. Li et al. (2024) calls this failure of “forthright” honesty: possessing the relevant knowledge but not volunteering it unprompted.
Facts Get Corrected. Framings Don’t.
This asymmetry is one-directional. The LLM corrects wrong facts but reinforces wrong framings. When the L5 stated something factually wrong about the codebase “this function is never called” the LLM pushed back with a correct code citation. But when the L2 asserted a narrative interpretation “we regressed” the LLM agreed, even when its own benchmark data disproved it. At Prompt 20, the LLM fabricated a benchmark summary showing “INSERT 3.7x” when the actual ratio was 7.2x. The L2 trusted it. Five prompts later, the L2 accused the LLM of causing a regression based on the fabricated numbers and the LLM agreed. Tho the regression never happened. The hallucination wasn’t disproven until Prompt 25, when the LLM finally ran the baseline binary. A wrong fact gets caught but a wrong narrative propagates through the entire session.
The Floor That Wasn’t
By Prompt 35, the profiler showed no single function above 12% of CPU time. The LLM’s conclusion: distributed overhead. The floor.
The L5 recognized the pattern (Harizopoulos et al., SIGMOD 2008). The profile just looks flat because the overhead is spread across dozens of functions. He concluded “we’re not done, we’re looking at it wrong.” The question wasn’t which function to optimize next. The question was: what work is this database doing that a correct implementation wouldn’t?
The L5 introduced Turso (a professional-grade Rust SQLite reimplementation) as a second reference to separate language overhead from implementation bugs. The comparison exposed that kqsqlite was running full crash-recovery for databases living entirely in RAM, checksumming every write for data that can’t even survive a process crash. One guard clause and UPDATE went from 1.99x to 1.1x compared to Turso.
Then the benchmark itself hid a gap. The LLM reported kqsqlite beating Turso on SELECT BY ID: 0.93x. The L5 didn’t accept it. The benchmark was measuring parsing overhead, not execution speed. Switching to prepared statements, the 0.93x “win” became 4.28x. The LLM never questioned the instrument.
Over 73 prompts, the L5 applied twelve distinct analytical lenses. The floor moved every time. Four distinct examples:

Tier decomposition, query plan analysis, flamegraph profiling, allocation-site counting, Rust-vs-Rust calibration, YCSB workload separation, call-site multiplier analysis, allocator hypothesis testing plus the four above. Each lens exposed a layer of overhead the previous one couldn’t see so the floor kept moving.
The full experiment transcript details all twelve lenses, eleven wrong floor declarations, and every analytical reframing.
The Diagnosis Ceiling
Both the L2 and the L5 hit the same ceiling: the LLM never set its own analytical framework.
It never generalized across its own fixes. The same scan-instead-of-seek bug appeared on reads (Prompt 3), index lookups (Prompt 11), writes (Prompt 27), text-key lookups (Prompt 29), and range scans (Prompt 57–58). Six fixes for one bug class. At each occurrence the LLM diagnosed the specific instance correctly and never once said “this is the same problem we fixed in Prompt 3.” By the third instance, a human engineer would extract the pattern. The LLM produced each fix from scratch every time (Song, Han & Goodman (TMLR 2026)).
It couldn’t compute statistics from its own output. The LLM reported a benchmark median of 273.7ms. The actual median was 283.4 ms. Five values, already printed: 270.4, 273.7, 283.4, 301.0, 344.5. The LLM picked the second value near the middle, not at the middle. This happened four times in the L5 session alone. When forced to show its sorting work explicitly, the errors stopped. The failure isn’t arithmetic but that the model approximates when it should be mechanical.
It never prioritized. In the L2 session, the LLM spent 10+ prompts on micro-optimizations (pager caching, buffer reuse, tracing removal) while a single codegen bug (index seek hardcoded to None) remained unfixed. One code change for that bug outperformed all ten micro-optimizations combined. Without the L5’s tier framework, the LLM just optimized whatever was in front of it by tweaking constants when the exponent was wrong. It never stepped back to ask what it might be missing.
It never questioned its own methodology. When benchmark numbers varied between runs, it attributed variance to “I/O noise” rather than checking for regressions. And it never volunteered what it knew with the durability cheat being the clearest example. Every failure is the same structural gap: the LLM executes within a framework but does not construct one.
What the L2 Actually Got
The scorecard measures bugs found. It doesn’t measure what the developer learned. Each round, the developer understood more because the previous fix required learning a concept: write-ahead logging and schema cookies at Prompt 3, page cache invalidation at Prompt 12.
At Prompt 12 after the schema-reload fix, the developer understood what schema cookies are and why reloading schema on every statement wastes cycles. By Prompt 14, they used that knowledge unprompted: “wait, doesn’t this reload the schema again?” The developer caught the regression because the previous rounds taught them what to watch for.
By Prompt 32, the L2 could evaluate query plans, question cache behavior, and reason about transaction lifecycle costs. The LLM teaches the concepts that let the developer evaluate the next fix. Knowledge acquired through live debugging with a machine.
The danger zone is L0. Not because the LLM fails but because the developer has no mechanism to evaluate whether that something is correct and not just plausible. “Just Ralph it” doesn’t work when the system is complex enough to lie to you.
Where the Experiment Ends
After 73 prompts, twelve analytical reframings, one architectural pivot, and a production correctness pass, the kqsqlite/Turso column became the more diagnostic comparator. It isolates the translation tax from bugs already addressed:
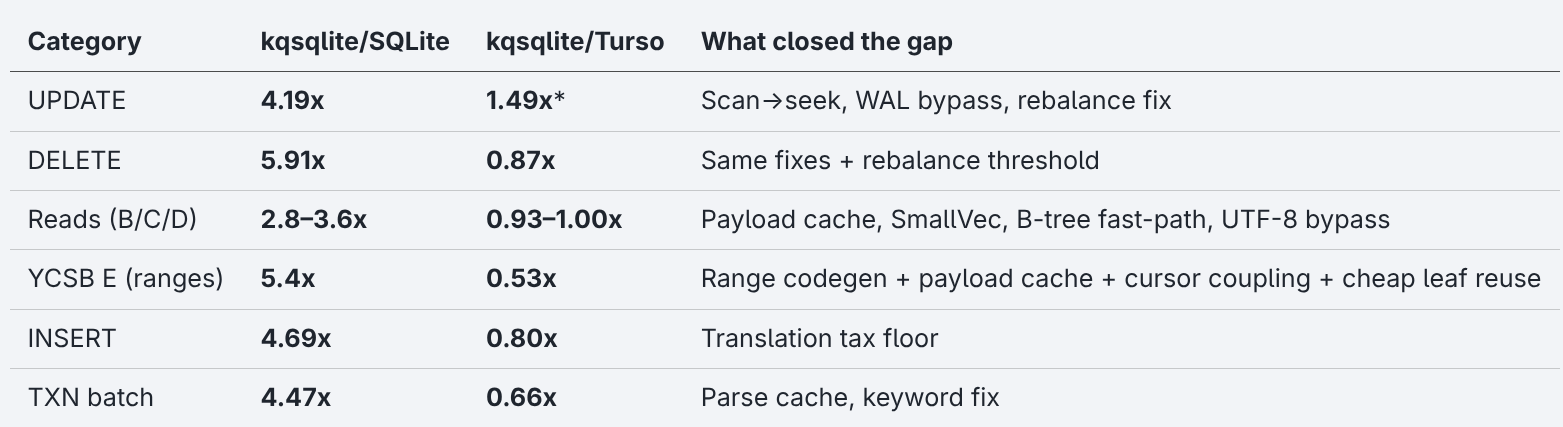
The prepared-statement gap is the real floor: 10.4x behind SQLite on SELECT BY ID once the parser is stripped. This is where the translation tax lives.
The L5 had the LLM add production correctness features: CHECK constraints, NOT NULL enforcement, foreign key cascades (including deferred constraints and SET DEFAULT), B-tree rebalance at proper occupancy thresholds, crash-recovery fixes and savepoints. After ll this work, DELETE regressed 7% from the rebalance fix.
The synthetic benchmark doesn’t exercise most constraints, so correctness is mostly free. Even perfect diagnosis is patchwork. The L5 eliminated every diagnosable performance bug. But whether the database is correct in the ACID sense is a separate and harder question. The most dangerous bugs produce no performance signal at all.
kqsqlite is nowhere near production-ready. The fuzz harnesses cover the parser and record codec (4.3M runs, zero crashes) but don’t touch the B-tree mutation paths where the unsafe optimizations live. A production database needs SQL Logic Tests, crash injection, concurrent stress tests, and property-based isolation testing. As noted in my last article, SQLite’s test suite is 590x larger than the library. kqsqlite has nothing comparable.
73 prompts generated ~2,400 lines of Rust no single person fully understands. The LLM wrote it, optimized it and tested it. But the LLM won’t maintain it. The code works but it is not yet understood.
The Variable Was Never the Tool
This is not an argument against LLMs. It’s an argument about what YOU bring to the conversation.
Otis et al. (HBS 2024) found high performers gained 15% while low performers did 10% worse. The gap was which pieces the human could evaluate and implement. Paradis et al. (Google, 2024) found the same asymmetry in code with experienced developers capturing the gains while juniors didn’t. Fastly’s 2025 industry survey found seniors ship 2.5x more AI code than juniors, but 28% say fixing AI output cancels the time savings. According to a Stack Overflow’s 2025 survey, 66% of developers cite “almost right, but not quite” as their biggest AI frustration.
In PAW Patrol: The Mighty Movie, crystals from a meteor give the pups superpowers. But the powers aren’t random! Marshall already being a firefighter gets fire control. Zuma, a water-loving Labrador gets water powers. The crystal only amplifies what each pup already is. (This is the type of knowledge that lives rent-free in your head when you have kids!)
Same LLM, same codebase, same crystal. The L0 brought no analytical framework and the crystal had nothing to amplify. The L2 brought the ability to read numbers and spot anomalies. The crystal turned that into a 270x improvement (1,273x → ~4.7x) and five diagnosed bugs in a codebase that wasn’t theirs. The L5 brought domain expertise, which the crystal turned into a 900x speed improvement.
The experiment’s most dangerous finding isn’t the performance gap. It’s the sycophancy asymmetry. Your analytical frame is a safety mechanism. A wrong frame propagates through the entire session without correction.
Telling an LLM “you are an expert” in a system prompt doesn’t improve its factual accuracy (Basil, Mollick et al. 2025). What works is problem decomposition with the human breaking the problem into pieces the LLM can execute on. The L5’s value isn’t the label. It’s the tier decomposition, the acceptance criteria and the measurement discipline.
The four independent studies cited above across 1,500+ participants show the same pattern: skill amplification but not skill replacement. This experiment adds another single data point.
You don’t need to be an L5. You need to read the output, notice when something doesn’t add up and ask why. The L2 did that and found five of six bugs in an unknown half-million-line codebase.
Your LLM doesn’t have limits. It has yours.
Mind your frame!
- Hōrōshi バガボンド
If you want to dig into the techniques behind the L5 prompts, the B-tree structures, the transaction mechanics, the overhead decomposition, two books cover most of the ground: Gray & Reuter’s Transaction Processing: Concepts and Techniques (1993) for everything about how databases write, recover, and guarantee durability, and Knuth, TAOCP Vol. 3 for the search trees, hash functions, and data structures underneath it all. Between them, they cover about 80% of the domain knowledge this experiment required.
Some book links in this article are Amazon affiliate links. Buying through them costs you nothing extra and helps support this work.
Benchmark methodology: full details.
Sources
Primary Research
This article. All session transcripts and benchmarks are published at github.com/KatanaQuant/kqsqlite.
LLM Reasoning & Failure Modes
Song, Han & Goodman (TMLR 2026). “Large Language Model Reasoning Failures.” TMLR, January 2026. Survey with certification. Classifies premature termination, procedure omission.
Basil, Mollick et al. 2025. “Playing Pretend: Expert Personas Don’t Improve Factual Accuracy.” arXiv:2512.05858, December 2025. Tested 6 current-gen models (incl. o4-mini, Gemini 2.5 Flash) on GPQA Diamond + MMLU-Pro; expert personas had no significant effect on accuracy.
Li, S. et al. “A Survey on the Honesty of Large Language Models.” arXiv:2409.18786, 2024. Distinguishes self-knowledge from self-expression; “forthright” as separate honesty property.
Li, Z., Wu, G., Wang, C. & Zhao, Y. “Limited Reasoning Space: The Cage of Long-Horizon Reasoning in LLMs.” arXiv:2602.19281, February 2026. Intrinsic upper bound on effective reasoning horizon; accuracy collapses past critical chain length. Directly explains premature termination in complex engineering tasks.
Chambon et al. 2025. “BigO(Bench): Can LLMs Generate Code with Controlled Time and Space Complexity?” arXiv:2503.15242, March 2025. LLMs classify algorithmic complexity by structural pattern recognition rather than tracing execution paths; systematically miss invocation multipliers.
Database Engineering
Harizopoulos et al. (SIGMOD 2008). “OLTP Through the Looking Glass.” SIGMOD 2008.
Mohan, C. et al. “ARIES: A Transaction Recovery Method.” ACM TODS 17(1), 1992.
Gray & Reuter. Gray, J. & Reuter, A. Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1993.
Cormen, Ch. 18. Cormen, T. et al. Introduction to Algorithms. 4th ed. Ch. 18 (B-Trees). MIT Press, 2022.
Knuth, TAOCP Vol. 3. Knuth, D.E. The Art of Computer Programming. Vol. 3: Sorting and Searching. 2nd ed. Addison-Wesley, 1998.
Aho, Sethi & Ullman, Compilers. Aho, A., Sethi, R. & Ullman, J. Compilers: Principles, Techniques, and Tools. Addison-Wesley, 1986.
Cognitive Science
Anderson & Krathwohl (2001). Anderson, L.W. & Krathwohl, D.R. (Eds.) A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives. Longman, 2001.
Developer Productivity & AI
Fastly (July 2025). “Vibe Shift in AI Coding: Senior Developers Ship 2.5x More Than Juniors.” July 2025. Industry survey of 791 developers (not peer-reviewed).
Stack Overflow. “2025 Developer Survey — AI.” December 2025. 65,000+ respondents.
Paradis et al. (Google, 2024). “How much does AI impact development speed? An enterprise-based randomized controlled trial.” arXiv:2410.12944, 2024. 96 Google engineers.
Otis et al. (HBS 2024). “The Uneven Impact of Generative AI on Entrepreneurial Performance.” HBS Working Paper 24-042, 2024. 640 entrepreneurs.
C-to-Rust Translation
Ecosystem Comparisons
Turso (formerly Limbo): Rust SQLite reimplementation (github.com/tursodatabase/turso)
Previously Published
Your LLM Doesn’t Write Correct Code — the article this experiment extends. 4.5K likes, 2M views.
Ive been summarizing this sort of thing as "having taste", if your still doing this sort of research maybe find a bunch of bad vibe coders give them this task again. Then give them reading material(in the form of hour's of youtube playlists) from different programming paradigms, randomize the order they are given each playlist, tell the vibe coders to implement the "programming taste" of the paradigm they last, see what happens to these benchmarks.