
20K LOC/Day Won’t Save You. They’ll Just Stack Plausibility.

3.9x faster writes than SQLite via multithreading with “mathematical near-impossibility of data corruption”
“Thesis proven.”
The most notorious limitation of SQLite, its single-writer bottleneck, finally solved.



Or is it?
TL;DR: Not really. It just appears that way!
What’s actually behind it is a Rust rewrite that is, despite the effort of adding 20,000 lines of code a day, still ~1,000x slower than SQLite because it’s paying for a concurrency feature that doesn’t actually fire.
LLMs don’t just write plausible code. They write plausible fixes, plausible benchmarks and plausible test suites too, stacking layers of plausibility, each inheriting the confidence of the layer above and the untested assumptions of the layer below.
If you read my last article about plausibility, the same rules apply here: I use these tools myself as a practitioner and this isn’t about one individual developer. It’s about a widely observed pattern I think we’ll all see more of in the future. A reader called this kind of project “a canary in the software engineering mines” or something like that (can’t find it anymore), which I really liked. I appreciate the canary! I think we all should.
The rewrite keeps getting advertised as the SQLite killer so I thought I’d have another look. How did 3.9x faster become ~1,000x slower? I followed the claim through the benchmark, the project’s concurrency mode and the layers underneath.
The “Only Benchmark That Matters”
I compiled and ran the YCSB-A benchmark, a standard database throughput benchmark, against SQLite and the Rust rewrite’s C API library. One shared table, 50/50 read/write split:
The benchmark source is available in this repository so you can reproduce it yourself. Absolute timings vary with system load and hardware. Ratios are what matter.
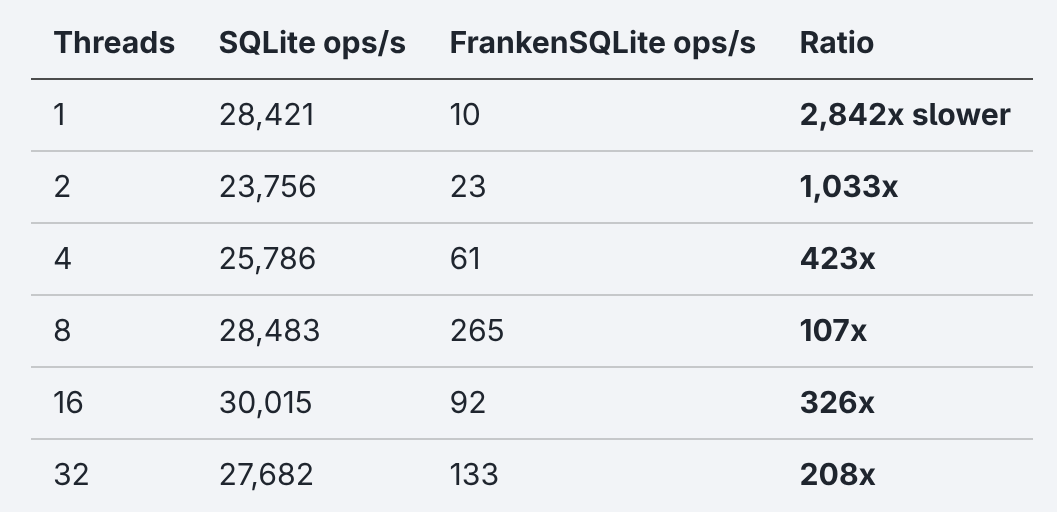
I’d say with 10 ops/s at one thread the rewrite isn’t really competitive. Tho the more interesting part lies in the multi-thread columns. Those are the ones the original post claimed to outperform by ~4x.
If it’s ~1,000x slower on two threads, how did the LLM come up with ~4x faster, claiming success?
Luckily the upstream repo includes their own benchmark, so I checked what’s happening inside. Three things jump out:
Each thread writes to its own table. Thread 0 into
bench_0, thread 1 intobench_1, etc. They never touch the same data. On its own, I’d call that fine for a micro-benchmark. But MVCC, the primary feature in the project’s README, exists so that multiple transactions can work with the same data without blocking each other. If two writers touch the same row, one of them gets stopped and retried. If they never compete, there’s nothing concurrent going on.SQLite gets forced into
BEGIN IMMEDIATE, a more aggressive locking mode than the defaultDEFERRED.BEGIN IMMEDIATEis the recommended approach for concurrent write-heavy work to avoid conflicts, but that’s not what’s being benchmarked here. There is no concurrency, only I/O parallelism across different tables.On top of that, every single row is its own transaction. This maximizes the overhead penalty SQLite has to pay per commit. 1,000 rows mean 1,000 commits. Real world databases batch hundreds or even thousands of rows per transaction. That’s what transactions are for! Paying the overhead cost without using its main feature defeats the entire purpose of transactions.
The benchmark is plausible: it runs and produces numbers. It even looks professional. It just doesn’t test what the README advertises and the post claims.
Brendan Gregg describes this anti-pattern in Systems Performance as the streetlight anti-method: analyzing with the tools you have rather than the tools the problem requires. The benchmark tested what was easy to measure (parallel I/O to separate tables) and avoided what was hard to measure (concurrent writes to shared data).
Or as Goodhart’s Law puts it: when a measure becomes a target, it ceases to be a measure. The 3.9x became the target. The only angle where that proof was possible for the LLM was a combination of separate tables, forced IMMEDIATE locking and single-row transactions. Any other combination would’ve shown the opposite.
After discovering that concurrency via MVCC wasn’t getting benchmarked, I gave SQLite the same parallel setup with one db file per thread for a fair head-to-head comparison:
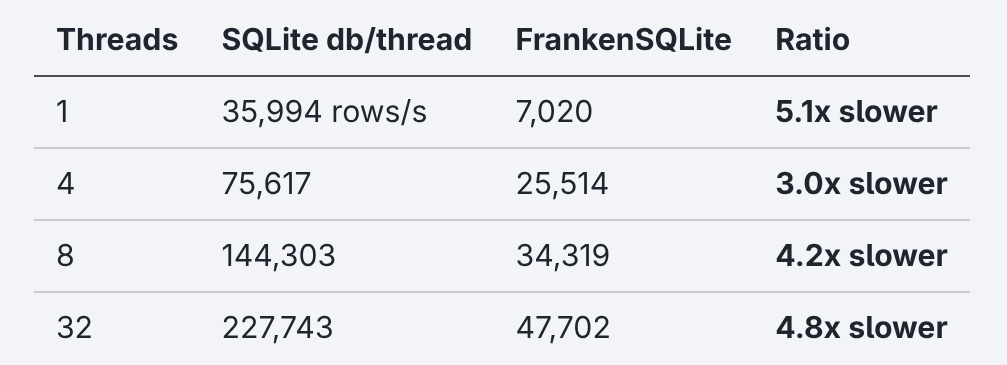
Even then, the rewrite is 3-5x slower. The ~4x advantage in their benchmark didn’t come from MVCC being fast. It came from finding the one configuration that artificially inflated SQLite’s bottleneck while not even measuring the thing being advertised anymore.
If you ask an LLM to write a benchmark that should prove you’re faster than SQLite, it’ll find one. But that doesn’t mean it makes sense!
If your workload truly has zero contention, with each writer on different data, you don’t need MVCC at all. Separate SQLite files give you 3-5x more throughput, zero complexity and SQLite’s full test suite behind it.
What about all the cases where you DO need MVCC tho? It’s probably okay to pay the concurrency overhead for a guarantee of zero data loss, right?!
Zero Aborts, Zero Concurrency
The project’s README promises “Serializable Snapshot Isolation preventing write skew by default.” This basically just means that when two transactions touch the same row, the database stops one of them and retries it later so it doesn’t act on stale data. After the first one finishes, the row is updated and the second one can continue. Otherwise you could get race conditions like exceeding an account’s balance when withdrawing at the same time.
To test whether the conflict detection actually fires, I ran an Elle-style isolation test: four threads withdrawing 100 from five shared accounts with a total balance of 1,000 whenever the balance allowed it.

Sure enough, there were no negative withdrawals. But if you look closely at that table, there were also no aborts? PostgreSQL caught 26 conflicts while the Rust rewrite caught 0.
If SSI is running, there HAVE to be aborts! Zero aborts means either nobody competed for the same data or the conflict detection isn’t firing. The SSI code is there (I checked). It also checks for the right things. But a zero on shared data means something else is going on.
So I used a very simple test to see if concurrency is even used here: four threads, each doing a write transaction and then waiting 100ms. If Multi-Version Concurrency Control is doing its job, all of them should converge on finishing within about 100ms. If they’re serialized, it’ll take 400ms.

Both variants, the sequential and the concurrent one, finish in the same 400ms. They behave the exact same way! This means both are fully serialized.
The reason for this is that FrankenSQLite’s pager, which manages all access to data on disk, sits behind a single global mutex. Only one thread goes through the mutex at a time, making all the others wait.
Kleppmann describes this approach in Designing Data-Intensive Applications: “The simplest way of avoiding concurrency problems is to remove the concurrency entirely: to execute only one transaction at a time, in serial order, on a single thread.”
There is no concurrency here.
BUT there is an MVCC layer sitting above the mutex, which does real work: it creates snapshots, tracks versions and builds conflict detection graphs. Every time it needs to actually touch data, it queues behind the same lock as everyone else.

The concurrency model can’t provide concurrency because the storage layer underneath won’t let it. You’re paying a 150x penalty for a feature that the mutex makes architecturally impossible to deliver. This is what a gap between layers looks like: the MVCC layer works, the pager layer works, the connection between them doesn’t.
The README itself contains a general caveat: “This README describes the target end-state architecture. The runnable code today is in a hybrid state.” Fair enough.
But the same README, in the same “Current Implementation Status” section, states: “fsqlite-vfs, fsqlite-pager, fsqlite-wal, fsqlite-mvcc, and fsqlite-btree are wired into default runtime execution.” The feature comparison table says “Concurrent writers: Many (page-level MVCC with SSI).” No asterisk or “planned.” It uses present tense. The caveat is scoped to “Native mode / ECS sections.” The concurrency claims are on the live side of that line.
A common response to my last article was “it’s not done yet” and again it might be tempting to say “just fix the concurrency and it’ll work.” And sure, software is always in progress. That’s exactly why “thesis proven” is the claim that needs the second measurement! The benchmark screenshot says 3.9x. The overlap test says 408ms. One of them measured a layer. The other measured a connection. The README’s own status section claims the MVCC stack is wired. My overlap test shows it isn’t.
The gap isn’t between “done” and “not done.” It’s between what’s claimed and what’s connected.
The Layers of Plausibility
The project’s test suite has 15,647 tests. A file called ssi_write_skew.rs tests the exact scenario I just ran and passes. correctness_concurrent_writes.rs contains a comment reading: “MVCC concurrent writer path is not yet wired.” The tests for it pass anyway. The tests validate each layer in isolation, where the code IS correct. They don’t test across the layers where it breaks.
And it’s not just the concurrency stack. The JOIN planner crashes at 12.3 GB of RAM on 375 rows, the C API exports only 19 of SQLite’s 220 functions. The pattern of plausible layers with untested connections runs through the entire project.
Steve Freeman and Nat Pryce argue in Growing Object-Oriented Software that tests exist to surface failures, not to confirm success. 15,647 tests that all pass. None of them fail where it matters: at the boundary between layers.
Frederick Brooks called these “the most pernicious and subtle bugs” back in 1975: system bugs arising from mismatched assumptions made by the authors of various components. Each layer of FrankenSQLite’s concurrency stack assumes the one below it works. None of them check.

The same pattern from my last plausibility article is at work here. If you read it top-down, everything looks correct: a mutex managing access, SSI detecting conflicts, transactions with proper isolation and a benchmark showing 3.9x. Again, the modules have the right names, the architecture makes sense and the tests pass.
Bottom-up, none of it connects. The claim comes from an invalid benchmark that validates a feature adding 150x overhead without doing what it promises. It can’t detect conflicts because the mutex above it serializes everything. All this work only for the mutex to provide isolation the same way SQLite does: by not allowing concurrency at all.
=== Building and running fsqlite-mvcc tests (SSI anomaly) ===
Running unittests src/lib.rs (target/release/deps/fsqlite_mvcc-285cac5b642bd309)
running 24 tests
[...]
test ssi_anomaly_tests::ssi_anomaly_write_skew_detected ... ok
test ssi_anomaly_tests::ssi_anomaly_phantom_insert_detected ... ok
[...]
test result: ok. 24 passed; 0 failed; 0 ignored; 0 measured; 1212 filtered out; finished in 2.51s
To be fair, some things did get better since the last article. On the single-threaded micro-benchmark, the path improved from 20,171x slower to about 9x. The WAL (write-ahead log) sync path was fixed, page copies were reduced and frame assembly was optimized. That’s real engineering! The things that got measured in response got better. Credit where it’s due.
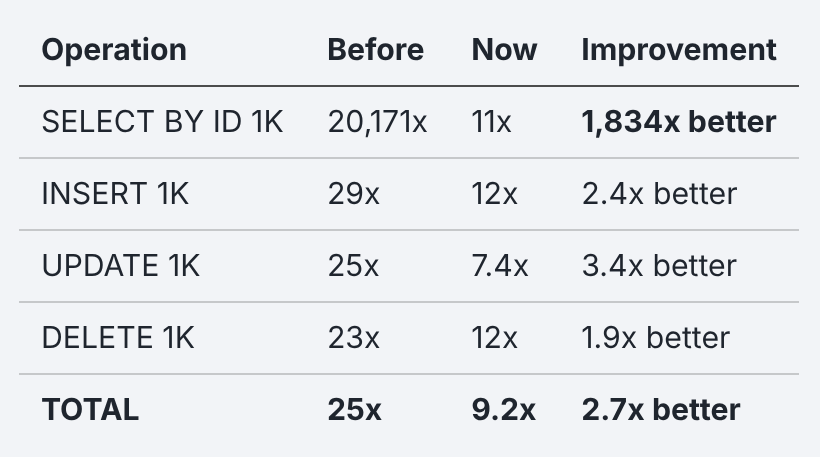
But the concurrency path, the one validated by the rigged benchmark, got worse. The 150x overhead wasn’t there before. It was added by enabling MVCC on every query without ever testing whether the concurrency it provides actually works. The measured path improved while the unmeasured path accumulated overhead.
For the ones thinking “it’s all refactorable, just replace the mutex and wire the layers.” Yes, probably. But you don’t refactor what you don’t know is broken. The SSI tests pass and the benchmark shows 3.9x. Every signal says green. The overlap test that would reveal the truth doesn’t exist in the repo because nothing suggested it was needed. That’s what plausible layers do: they don’t just hide bugs from reviewers, they hide them from the developer too.
During my own experiment with this codebase, where I tried improving its performance by only prompting, there was a moment where the LLM produced a benchmark showing INSERT at 0.70x, faster than SQLite. My first reaction wasn’t to celebrate but to stop and ask what’s wrong.
Turns out the LLM had silently batched 64 autocommit statements into one transaction, changing the durability guarantee. When I asked it about the speed increase directly, it admitted: “This is cheating.”
The LLM’s own reply called it cheating. It just didn’t volunteer that until asked directly. The 3.9x benchmark has the same structure: it measures something real, just not the thing being claimed.
So what does it look like when concurrent writes actually work?
How Concurrency Layers Actually Work
PostgreSQL has had working Serializable Snapshot Isolation since 2011. The FrankenSQLite spec document even cites the Ports and Grittner paper that documented it.
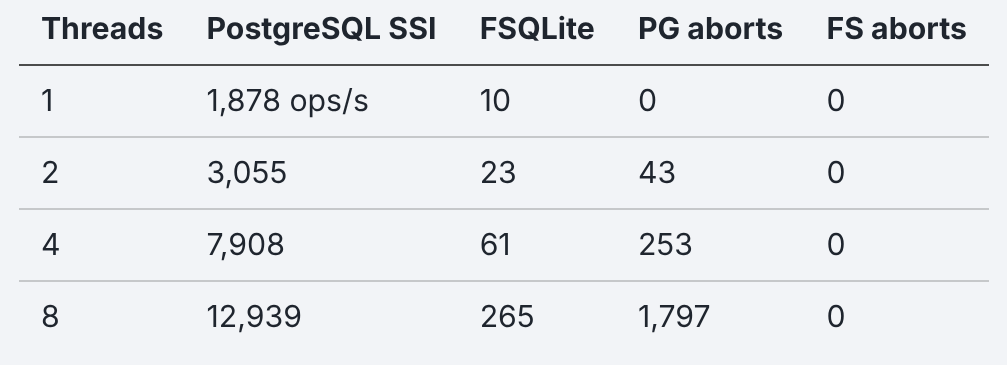
Even though FrankenSQLite runs in-process with zero network cost, PostgreSQL, a server where every query pays a network round-trip, is still 188x faster at 1 thread.
Three deliberate engineering choices explain the gap:
PostgreSQL doesn’t funnel all page access through one lock. It uses per-page lightweight locks so transactions on different pages proceed in parallel. FrankenSQLite has a single
Arc<Mutex>for the entire pager.In PostgreSQL transactions overlap by design.
BEGINgrabs a snapshot without holding a lock. OnlyCOMMITbriefly validates and serializes. My overlap test showed FrankenSQLite takes 400ms for what should take 100 because nothing overlapped.PostgreSQL pays for serializability in aborts. 253 at 4 threads, 1,797 at 8. That’s the cost of actually checking whether two transactions stepped on each other. FrankenSQLite pays 150x overhead and checks nothing.
Each of these is a connection between layers that PostgreSQL tests and FrankenSQLite doesn’t. Locks connect the pager to concurrent access. Overlap connects transactions to the scheduler. Aborts connect SSI to the commit path. In FrankenSQLite, every one of these connections is missing while every individual layer passes its own tests.
Confidence Outruns Evidence
Speed builds plausible layers. Plausible layers hide the gaps. Hidden gaps don’t get tested. Untested gaps don’t get refactored. And the system ships with metrics that say it works.
20,000 lines a day over hundreds of commits in weeks, and only a handful about performance. The debt accumulated faster than anyone could evaluate it. Every layer was plausible. Every test passed. Every metric said green. And the one measurement that mattered - do the layers actually connect - was never written because every signal said it wasn’t needed.
Domain knowledge is key. I wrote about this in The Bug That Shipped: the LLM knows about the bugs. It just doesn’t volunteer the information unless you ask the right question. And knowing which question to ask is the part that can’t be automated. You need to know that zero aborts on contended data is wrong. You need to know that “faster than SQLite”, a 25-year-old codebase, means something changed that shouldn’t have.
My last article closed with: “The vibes are not enough. Define what correct means. Then measure.”
The response was 20,000 lines of code per day.
The second measurement is the one that was missing. The first one tested layers. The second one tests the connections between them. Before shipping the next feature, stop and ask yourself: am I measuring what I think I’m measuring? Or am I just measuring what’s easy to measure?
15,647 tests said green. The overlap test that would have said red took 10 lines of C.
LLMs are useful. 20,000 lines a day is useful. But speed without the second measurement is just plausibility at scale.
Or as Mario Zechner puts it: “Slow the F down.”
Benchmarks run against FrankenSQLite at commit 12b18f9b (March 25, 2026; 952 commits post-squash), PostgreSQL 16, and SQLite system library. All sqlite3-compatible benchmarks use the C API. Concurrent benchmarks are file-backed (required for multi-connection access). Benchmark harness: db_bench_foo. FrankenSQLite’s own benchmark: concurrent_write_persistent_bench.rs.
Sources
Some book links are Amazon affiliate links. Buying through them costs you nothing extra and helps support this work.
Concurrency Control & Isolation
Kleppmann, M. Designing Data-Intensive Applications. O’Reilly, 2017. Chapter 7: Transactions.
Ports, D., Grittner, K. “Serializable Snapshot Isolation in PostgreSQL.” VLDB 2012.
Benchmark Methodology
Cooper, B. et al. “Benchmarking Cloud Serving Systems with YCSB.” SoCC 2010.
Kingsbury, K., Alvaro, P. “Elle: Inferring Isolation Anomalies from Experimental Observations.” VLDB 2021.
Systems Performance & Anti-Patterns
Gregg, B. Systems Performance: Enterprise and the Cloud. 2nd ed. Addison-Wesley, 2020.
Brooks, F. The Mythical Man-Month. Addison-Wesley, 1975.
Freeman, S., Pryce, N. Growing Object-Oriented Software, Guided by Tests. Addison-Wesley, 2009.
SQLite Documentation
Related Writing
Zechner, M. “Thoughts on Slowing the Fuck Down.” March 2026.
Benchmarks & Evidence
Benchmark harness: db_bench_foo (open source, reproducible).
FrankenSQLite’s own benchmark: concurrent_write_persistent_bench.rs.